Glue
- Managed ETL service
- Used to prepare and transform data FOR analytics
- does not perform analytics in and of itself
- Fully serverless
Glue Data Catalog
-
Catalog of datasets
-
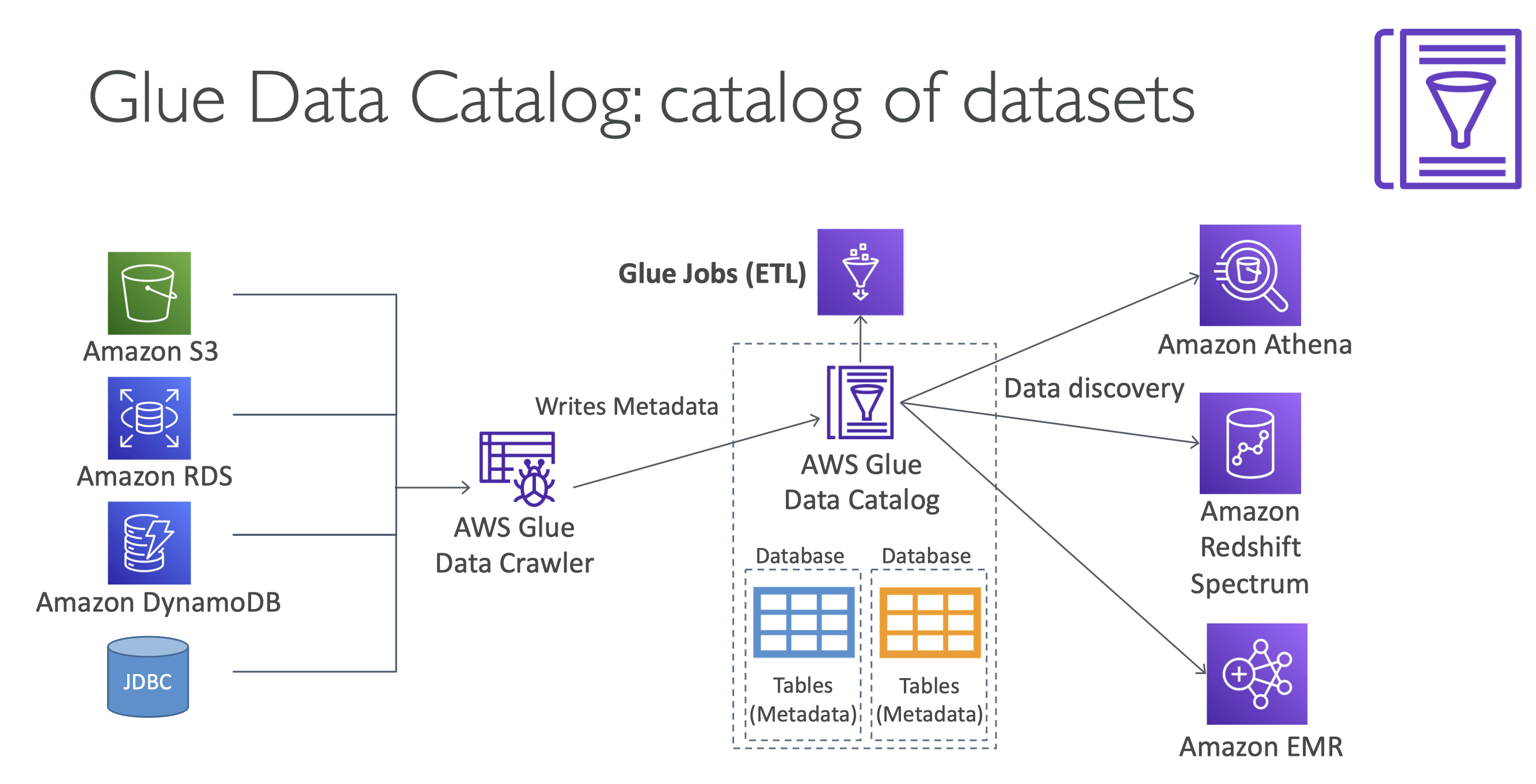
-
saa_exam_alerts know about how to use Glue to transform data into the Apache Parquet format
- columnar data format
- therefore, better for use in a service such as Athena
- columnar data format
-
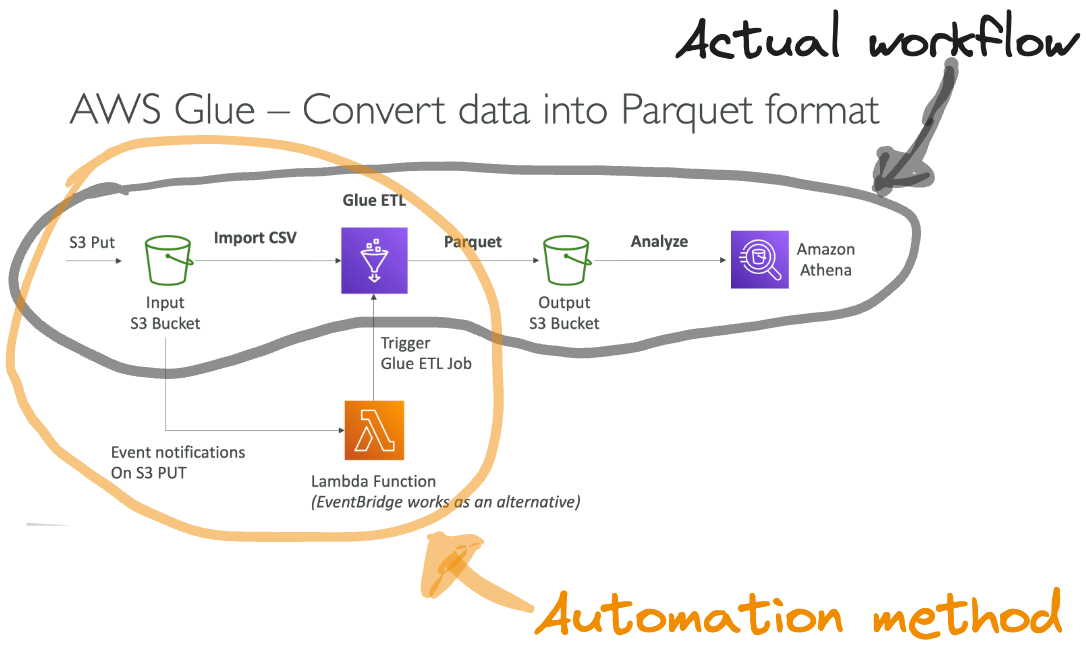
ChatGPT Overview
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy for customers to prepare and load their data for analytics. It simplifies the process of preparing and transforming data for analytics and machine learning (ML) by providing tools for discovering, cataloging, cleaning, enriching, and transforming data at scale. Here’s an overview of AWS Glue’s key features and capabilities:
1. Data Catalog:
- Overview: AWS Glue includes a centralized metadata repository called the AWS Glue Data Catalog. It acts as a persistent metadata store for all your data assets, including databases, tables, schemas, and partitions.
- Benefits: The Data Catalog provides a unified view of your data assets across various data sources and formats, making it easier to discover and understand your data. It also improves data governance, data lineage tracking, and data access control.
2. ETL Jobs:
- Overview: AWS Glue allows you to define and run ETL (extract, transform, load) jobs to process and transform your data. ETL jobs can be created using a visual editor or written in Apache Spark, a distributed processing framework for big data.
- Benefits: ETL jobs automate the process of data preparation and transformation, reducing the time and effort required to prepare data for analysis or consumption by downstream applications. They enable you to cleanse, normalize, aggregate, and enrich data before loading it into data lakes, data warehouses, or analytics platforms.
3. Crawlers:
- Overview: AWS Glue provides crawlers that automatically discover and catalog metadata about your data assets. Crawlers analyze data in various formats and locations, such as Amazon S3, RDS databases, DynamoDB tables, and data streams.
- Benefits: Crawlers eliminate the need for manual metadata management by automatically scanning and cataloging data sources. They ensure that the Data Catalog remains up to date with the latest information about your data assets, enabling efficient data discovery and querying.
4. Data Transformation:
- Overview: AWS Glue supports data transformation capabilities using Apache Spark, a powerful distributed processing engine. You can write custom transformations using Spark’s APIs or leverage built-in transformations provided by AWS Glue.
- Benefits: Data transformation enables you to cleanse, enrich, and reshape your data to meet the requirements of downstream analytics and ML applications. It allows you to perform complex data processing tasks, such as joining multiple datasets, aggregating data, and applying business logic.
5. Serverless Architecture:
- Overview: AWS Glue is built on a serverless architecture, meaning that you don’t need to provision or manage infrastructure. AWS automatically scales resources up or down based on the demand, ensuring high availability and cost efficiency.
- Benefits: Serverless architecture simplifies deployment and management, allowing you to focus on building and running ETL jobs without worrying about infrastructure provisioning, scaling, or maintenance.
6. Integration with Other AWS Services:
- Overview: AWS Glue integrates seamlessly with other AWS services, such as Amazon S3, Amazon Redshift, Amazon RDS, Amazon Aurora, Amazon DynamoDB, and Amazon EMR.
- Benefits: Integration with AWS services enables you to ingest data from various sources, store it in data lakes or warehouses, and analyze it using analytics and ML services. It provides a comprehensive data integration and analytics platform within the AWS ecosystem.
AWS Glue is suitable for a wide range of use cases, including data warehousing, data lakes, analytics, reporting, and ML. It helps organizations accelerate the process of data preparation and transformation, enabling faster insights, better decision-making, and enhanced data-driven capabilities.